こんにちは、エンジニアのオオバです。
GitHub - mogeta/calm_down
上記、同僚がLTでCloud Speech-to-Textを使ったマイクロサービスを作っていたので、ぼくも触ってみようということで、触ってみたという記事です。
Speech-to-Text: 自動音声認識 | Google Cloud
ちなみにCloud Speech-to-Textとは、Google製のAI テクノロジーを搭載したAPIで、音声をテキストに変換してくれるクラウドサービスです。
→11万文字で徹底解説した「DOTweenの教科書」Unityアニメーションの超効率化ツールはこちら
公式ドキュメントに従っていく
クイックスタート: クライアント ライブラリの使用 | Cloud Speech-to-Text ドキュメント | Google Cloud
基本的にはこちらのページのSpeech-to-Textの公式ドキュメントに従っていきます。
今回は「TestCloudSpeechApp」という新規プロジェクトを作成します。
プロジェクトの作成と設定
ドキュメントの通り以下の作業をします
- プロジェクトの作成
- サービス アカウントの作成
- 秘密鍵のダウンロード
- プロジェクトに対して Cloud Speech-to-Text API を有効にする

プロジェクトの設定ボタンをクリックします。
Configure a billing accountという警告
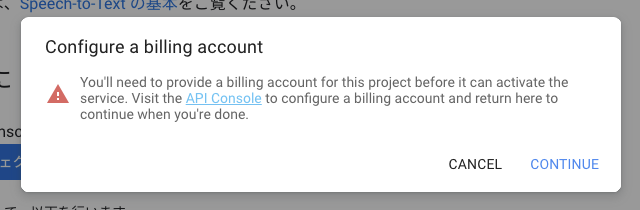
警告内容に従い、課金アカウントを作成するため 「CONTINUE」ボタンをクリックします。
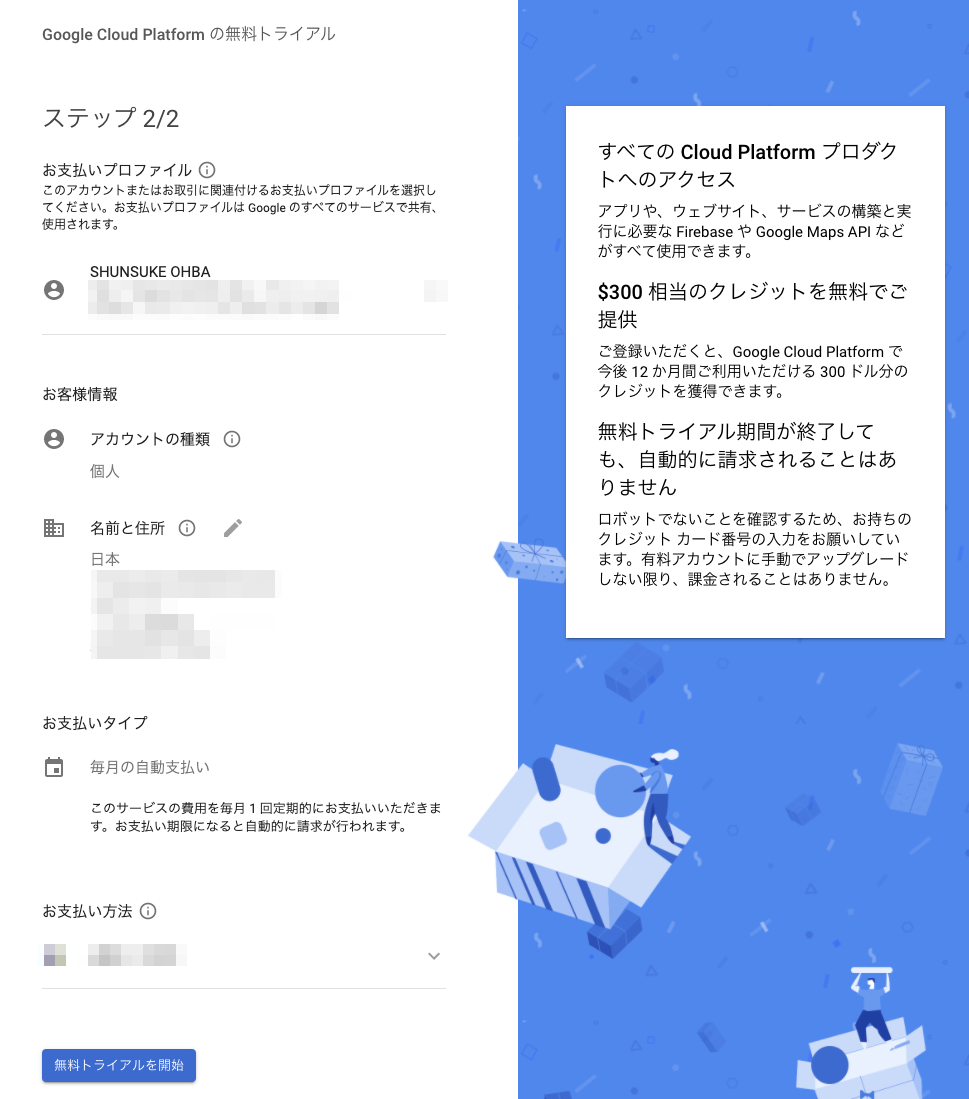
案内に従っていき、無料トライアルを開始します。

すると1年間有効の300ドルが付与されます。

請求先アカウントを作成をクリックします。
おそらくこの工程が2. サービス アカウントの作成です。
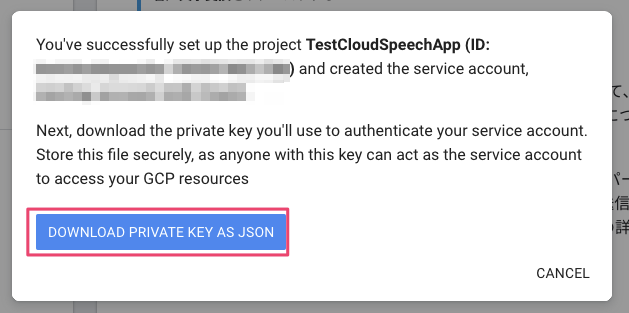
このような画面になるので、 DOWNLOAD PRIVATE KEY AS JSONをクリックして秘密鍵のJSONをダウンロードしておきます。
この工程が3. 秘密鍵のダウンロードです。

そして先程作成したプロジェクトのCloud Speech-to-Text APIを有効化します。NEXTボタンをクリック。
この工程が4. プロジェクトに対して Cloud Speech-to-Text API を有効にするにあたります。
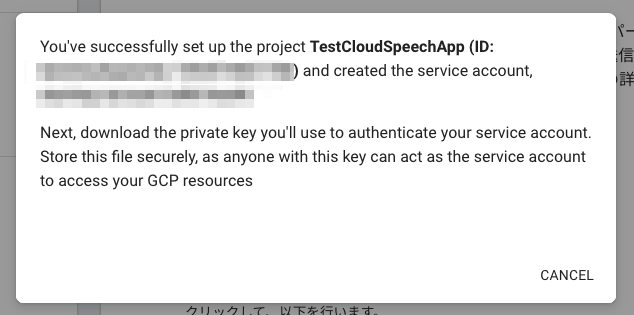
準備が完了しました。
環境変数 GOOGLE_APPLICATION_CREDENTIALS を、サービス アカウント キーが含まれる JSON ファイルのパスに設定します。この変数は現在のシェル セッションにのみ適用されるため、新しいセッションを開く場合は、変数を再度設定してください。
.bashrcや.bash_profileなどに
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]"
という一行を追加してパスを通します。
"[PATH]"には先程ダウンロードした秘密鍵のJSONまでのパスを記述します。
一旦ここまでがプロジェクトの設定です。引き続き公式ドキュメントに沿って作業します。
Cloud SDKのインストールと初期化
Cloud SDK のドキュメント | Google Cloud
こちらのドキュメントに従います。
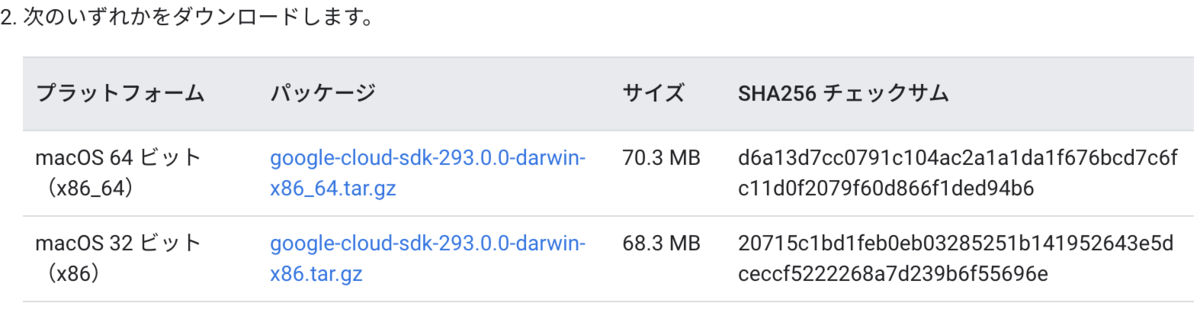
まずは、SDKをダウンロードしてきます。
インストールのシェルを実行。
sh install.sh
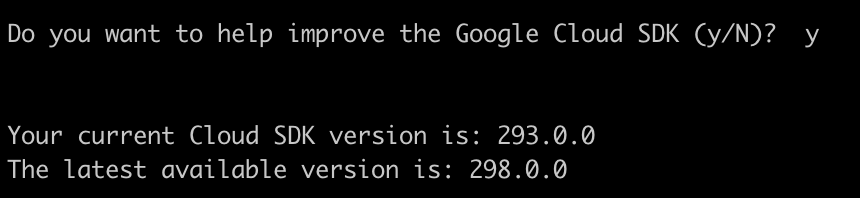
アップデートしてよいかと問われたので、アップデートを選択。

既存設定をいじりたくなかったので(というか忘れているので)、新規で設定を作ることを選択。

設定名を入力。
※起動は
-のみ使用可能 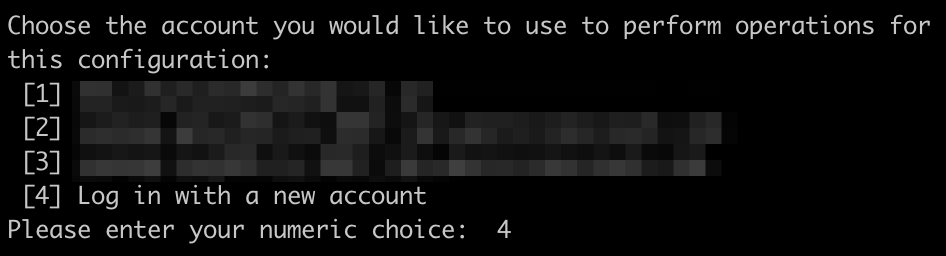
ログインするGoogleアカウントを選択。

先程作ったプロジェクトを選択。今回は
TestCloudSpeechAppを選択しています。 
成功するとこのような表示になります。
そろそろクライアント作業に入ります。
音声文字変換をリクエストするサンプルコードを動かす
クライアント ライブラリのインストール
今回は初めてですがGoを選択します。
go get -u cloud.google.com/go/speech/apiv1
とシェルで実行してライブラリをインストールしておきます。
Page not found · GitHub · GitHub
こちらのコードを動かしてみます。コピーして、helloworld-speech-to-text.goというファイルを作成してペーストしておきます。
実行
go run helloworld-speech-to-text.go
案の定失敗
Failed to read file: open /path/to/audio.raw: no such file or directory
exit status 1
エラー内容から、
ソースコードの/path/to/audio.raw部分を自分で用意した音声ファイルを突っ込む必要がありました。
Googleさん音声ファイルを用意しておいてよ〜って思ってたんですが、この記事を書き終えた後に気づきましたが、C#の方のサンプルにはアップロードされていました。
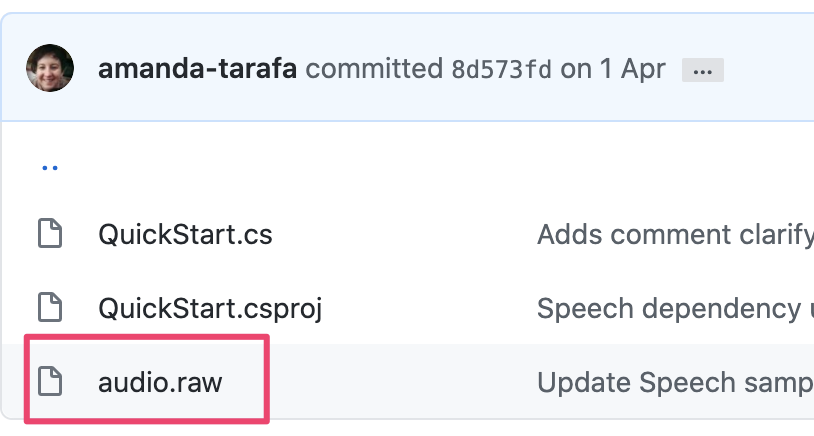
Page not found · GitHub · GitHub
QuickTimeで音声収録してwavに変換
ここから自分の音声ファイルを作成していきます。

Macの場合はQuickTimeでお手軽に収録できます。手持ちのMacBookにはマイクも付いているので、特に機材用意もなく収録できます。

QuickTimeからはm4aというフォーマットで保存されます。
m4aでは失敗したのでwavへ変換
m4aでも試しましたが、失敗してしまったので、間違いなさそうなwav形式に大好きなffmpegで以下のようなコマンドでサクッと変換します。
ffmpeg -i sample.m4a sample.wav
※ffmpegが未インストールだった場合はbrew install ffmpegしてください

サンプルコードのfilenameの部分をリネーム。
再度Goを実行します。
go run helloworld-speech-to-text.go
認識された!!

ドライな感じでコンソールに出力されただけですが、ぼくの音声(Hello)がちゃんと「Hello」と認識されて少し感動しました。
途中ですが最後に
同僚のマイクロサービスを動かすところまでは本記事では到達できませでしたが、Cloud Speech-to-Textを使うところまではできました。
ほぼほぼプロジェクト設定周りに時間を食われた形ですが、動いてよかったです。
ぼくの肉声ファイルを含む全ソースを以下にアップしておきます。
GitHub - baobao/helloworld-speech-to-text: Helloworld Speech-to-Text
副次的に学んだこと
音声をシェルから再生させて、情報を知る
SoX - Sound eXchange download | SourceForge.net
brew install SoX
brewからインストールして使いました。
play sample.wav
と実行すると指定した音声が再生され音声情報も表示されます。
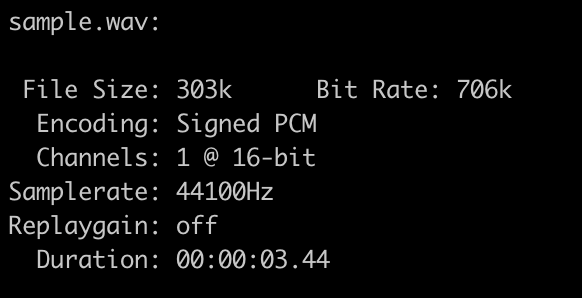
シェルから実行できるのはちょっと便利。
ffmpegでトリミング
インターネットから音声ファイルを落としてきた時に、やたら長かったので、サクッとffmpegでトリミングできないかなと調べていたら、良い参考記事がありました。ありがとうございます。
ffmpeg で指定時間でカットするまとめ | ニコラボ
ffmpeg -i input.wav -t 3 output.wav
みたいに -tオプションでトリミングができます。

この記事が気に入ったらフォローしよう
